The City of Edmonton released its annual Growth Monitoring Report recently, known as Our Growing City. At 90 pages it’s full of information. Here are some things I wanted to highlight!
Upward, Inward, Outward?

The report (and associated infographic) likes to talk about how Edmonton is growing up, in, and out. But is it really?
Several key initiatives demonstrate how this vision guides Edmonton’s growth. The Quarters Downtown, West Rossdale, Blatchford, downtown redevelopment, and Transit Oriented Development are helping our central neighbourhoods and areas along Edmonton’s expanding LRT routes grow “upward.” Ongoing efforts to enable infill opportunities in our mature and established neighbourhoods help the city grow “inward,” and the construction of new neighbourhoods in developing areas enables our city to grow “outward.”
The truth is that developing neighbourhoods, the “outward” part of growth, account for the majority of residential development. The report states that as in 2013, “developing neighbourhoods accounted for 83% of all residential growth” last year. Our city continues to grow out much more quickly than up or in.
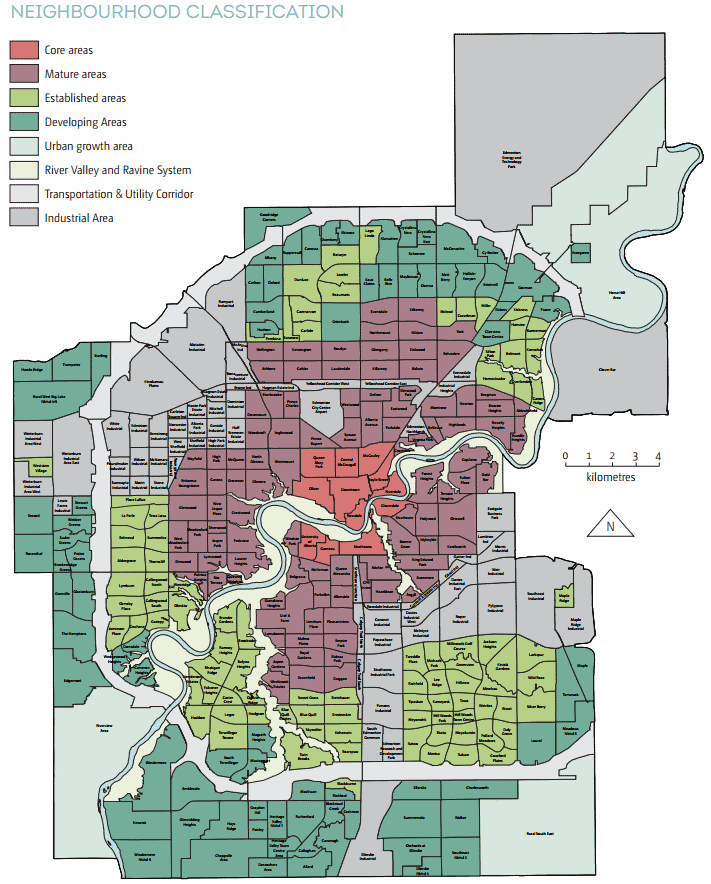
You can see the neighbourhood classifications on a map here.
Core neighbourhoods accounted for 8% of all growth in 2014 while mature neighbourhoods accounted for just 6%. “This is an increase of 18% from 2013 unit growth (704 units),” the report says. “It is, however, a relatively low proportion of city-wide growth due to strong increases in newer neighbourhoods.” Established neighourhoods accounted for 3% of all new units.
Nine of the top ten fastest growing neighbourhoods over the last five years are in the south.
The fastest growing are Summerside, The Hamptons, and Windermere.
The only potential bright spot here is that recent NSPs tend to plan more dense communities and “contain a more balanced range of dwelling types” than they have in the past. Here’s a look at the density map:
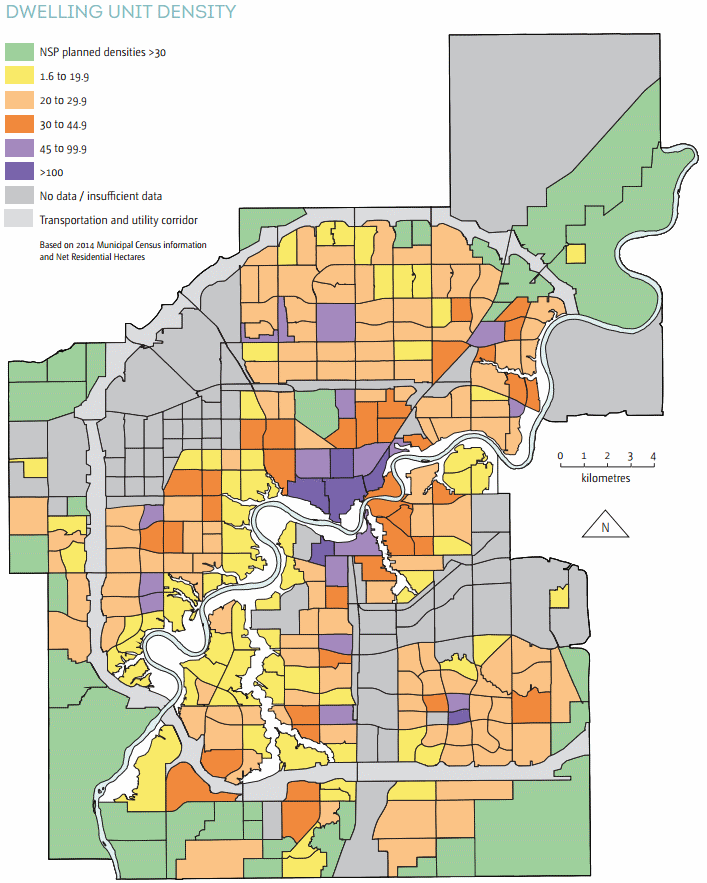
You can see that the new areas around the edge may actually be more dense than existing communities in mature and established neighbourhoods. If we don’t do anything to increase the density of those areas, that is.
Demographic Shifts
As of June 30, 2014 the Edmonton CMA had 1,328,290 residents, up 3.3% over the same time in 2013. We’re the second fastest growing CMA in the country after Calgary. And we’re comparatively young.
The Edmonton CMA is comparatively much younger than major Canadian city regions with a median age of 36 years.
Most other cities have a media age of 39-40 years. Our city’s largest cohort is 25-39 years of age, followed by the 49-65 age group.
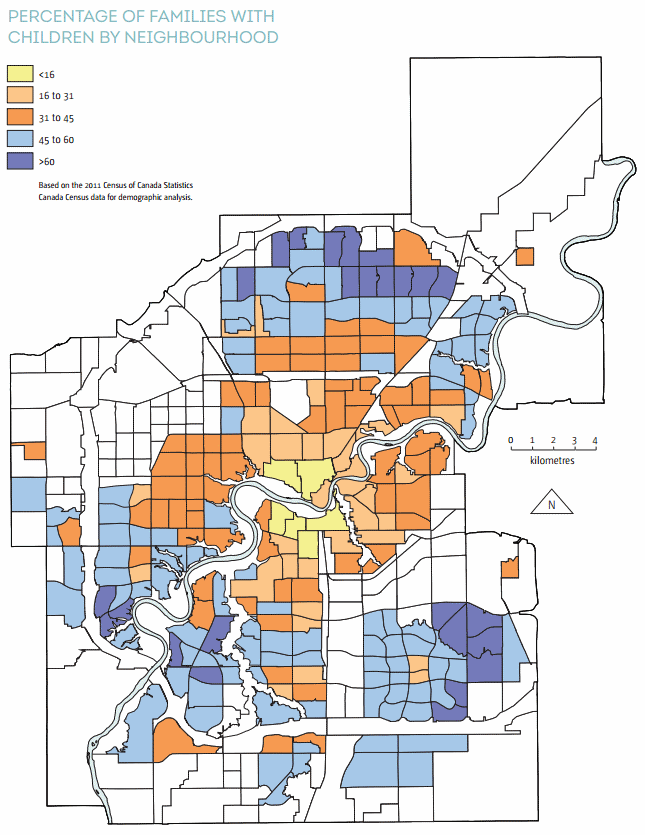
You might think with all of those young people that we’d have more families. And maybe we do, but not in established parts of the city.
A demographic shift is occurring in mature and established areas of the city. The population is ageing and households are decreasing in size. There will be a significant increase in lone person and two person households.
It’s a complicated issue, but ageing in place means that young families are pushed to the developing areas (as shown in the above map), which means we have to build new schools, recreation facilities, etc. It means we continue to grow outward.
Regional Competition
In 2014, 71% of all housing starts in the Edmonton region occurred within the city, which is better than the 10 year average of 66% (our high was 94% in 1982 and our low was 53% in 1996). But remember, the bulk of our growth is happening in developing areas, and that often means single-detached homes.
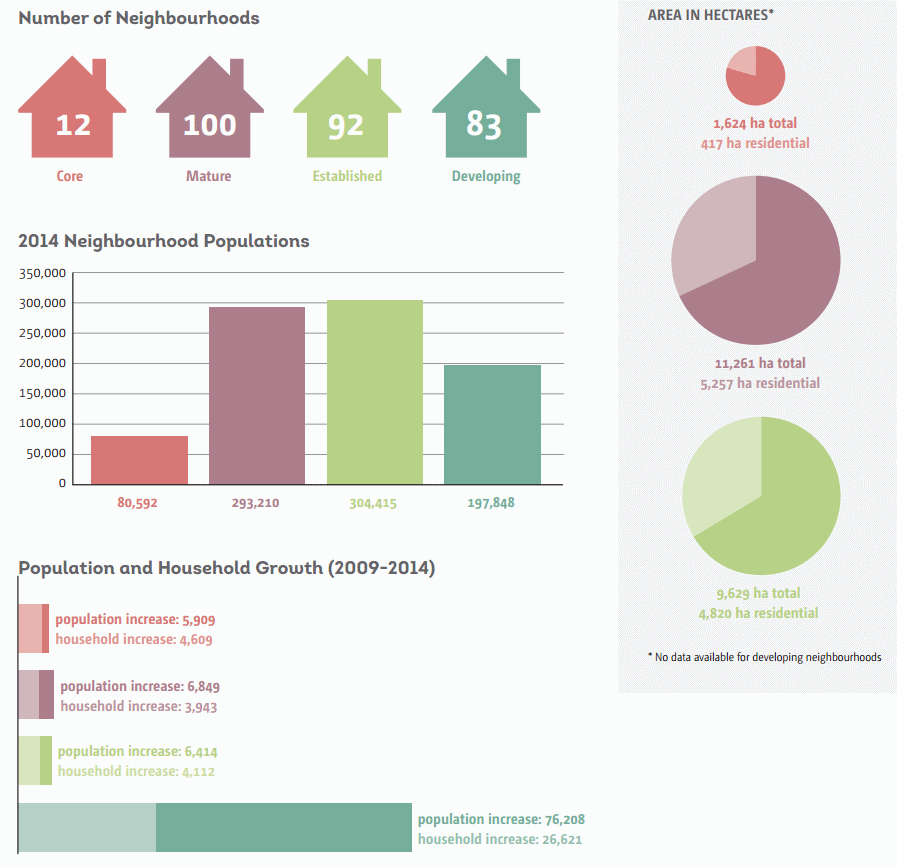
Our share of regional single-detached housing starts over the last 10 years has averaged 59%. We don’t have much competition when it comes to folks wanting to live in condos or apartments. But for single family homes, there are lots of options just outside Edmonton’s boundaries. And this is a problem because surrounding communities don’t build communities that are as dense as the ones Edmonton is building.
Zoning & Annexation

The report states that the Edmonton region is expected to grow to just under 2.2 million by 2044, with the city itself reaching 1.4 million people by that time. Looking further to 2064 our city’s population is expected to grow to 2.1 million. All those people are going to have to live somewhere, so “approximately 270,000 new housing units” are required to handle the anticipated growth.
This is why the City is pursuing annexation.
“The City of Edmonton is quickly running out of room to accommodate anticipated growth. This is especially true for industrial lands but is also true for residential developments.”
We’re only “quickly” running out of room because our growth pattern hasn’t changed much. There is room to grow inward:
Edmonton’s core, mature and established neighbourhoods share a total of 180 ha of vacant land, with the distribution of this land varying widely amongst them. In total, 1,343 vacant lots have been identified within the central core, mature and established neighbourhoods.
That vacant land could house an additional 3,287 dwelling units and potentially 7,725 people, based on existing zoning. If we re-zoned land and consolidated some lots the potential could be even higher. Not enough for all of the anticipated growth, but more than we’re on track to house centrally.
For the last decade or so, a 2:1 ratio of residential to industrial/commercial land area has continued in Edmonton.
“Without annexation, Edmonton will exhaust its industrial supply of land in 10 years and its residential in 12 to 17 years. The proposed annexation ensures that both industrial and residential land inventories meet the policy target of maintaining a minimum 30-year supply.”
The need for more industrial land is what’s really driving the two currently proposed annexations, in Leduc County and Sturgeon County.
In Edmonton the current proportion of zoned land uses is roughly 32% residential, 3% commercial, 12% industrial, 7% institutional and 9% parks and open space, special “direct control” zones account for 4% of land uses, Transportation Utility Corridor (TUC) 6% and 27% agriculture.
That’s a big drop in agricultural and reserve land, which was at 37% previously. “For the past decade Edmonton has been converting an average of 1,000 hectares of agriculture and reserve zoned land into urban zones.”
More Information
You can learn much more about Edmonton’s growth at the City’s website.
There are also some useful data sets in the open data catalogue. Here are a few that are relevant (but there are dozens):
- 2014 Census – Population by Structure Type (Neighbourhood)
- Vacant Land Inventory
- Mature Neighbourhood Reinvestment
What else did you find interesting in the report?












 Today I’m excited to share the news that Open Data has arrived in Edmonton! In a presentation to City Council this afternoon, Edmonton CIO
Today I’m excited to share the news that Open Data has arrived in Edmonton! In a presentation to City Council this afternoon, Edmonton CIO 
 The City of Edmonton’s data catalogue is built on Microsoft’s
The City of Edmonton’s data catalogue is built on Microsoft’s 
{kind=link}