For the last five years or so, IDC has released an EMC-sponsored study on “The Digital Universe” that looks at how much data is created and replicated around the world. When I last blogged about it back in 2008, the number stood at 281 exabytes per year. Now the latest report is out, and for the first time the amount of data created has surpassed 1 zettabyte! About 1.2 zettabytes were created and replicated in 2010 (that’s 1.2 trillion gigabytes), and IDC predicts that number will grow to 1.8 zettabytes this year. The amount of data is more than doubling every two years!
Here’s what the growth looks like:
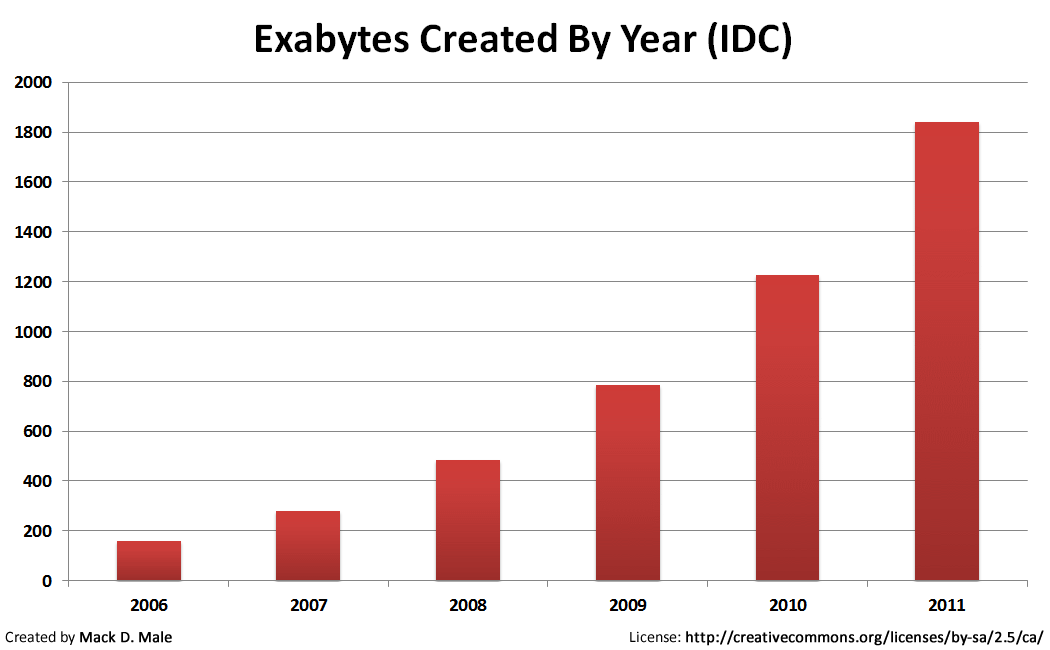
How much data is that? Wikipedia has some good answers: exabyte, zettabyte. EMC has also provided some examples to help make sense of the number. 1.8 zettabytes is equivalent in sheer volume to:
- Every person in Canada tweeting three tweets per minute for 242,976 years nonstop
- Every person in the world having over 215 million high-resolution MRI scans per day
- Over 200 billion HD movies (each two hours in length) – would take one person 47 million years to watch every movie 24/7
- The amount of information needed to fill 57.5 billion 32GB Apple iPads. With that many iPads we could:
- Create a wall of iPads, 4,005 miles long and 61 feet high extending from Anchorage, Alaska to Miami, Florida
- Build the Great iPad Wall of China – at twice the average height of the original
- Build a 20-foot high wall around South America
- Cover 86 per cent of Mexico City
- Build a mountain 25 times higher than Mt. Fuji
That’s a lot of data!
EMC/IDC has produced a great infographic that explains more about the explosion of data – see it here in PDF. One of the things that has always been fuzzy for me is the difference between data we’ve created intentionally (like a document) and data we’ve created unintentionally (sharing that document with others). According to IDC, one gigabyte of stored data can generate one petabyte (1 million gigabytes) of transient data!
Cost is one of the biggest factors behind this growth, of course. The cost of creating, capturing, managing, and storing information is now just 1/6th of what it was in 2005. Another big factor is the fact that most of us now carry the tools of creation at all times, everywhere we go. Digital cameras, mobile phones, etc.
You can learn more about all of this and see a live information growth ticker at EMC’s website.
This seems as good a time as any to remind you to backup your important data! It may be easy to create photos and documents, but it’s even easier to lose them. I use a variety of tools to backup data, including Amazon S3, Dropbox, and Windows Live Mesh. The easiest by far though is Backblaze – unlimited storage for $5 per month per computer, and it all happens automagically in the background.
 I typed the title for this post into Windows Live Writer, and a red squiggly appeared under the word “exabytes”. I just added it to the dictionary, but I can’t help but think that it’ll be in there by default before long.
I typed the title for this post into Windows Live Writer, and a red squiggly appeared under the word “exabytes”. I just added it to the dictionary, but I can’t help but think that it’ll be in there by default before long.